Kubernetes: kube-scheduler をソースコードレベルで理解する
はじめに
Kubernetes において、Pod を配置するための Node を決定する手続きをスケジューリングと呼び、デフォルトのクラスタでは kube-scheduler がその責務を担っています。本記事ではこの kube-scheduler のソースコードを時系列に沿って追いつつ、どのようなロジックで Pod を配置する Node が決定されるのかを解説します。
なお、本記事は Kubernetes の内部実装について学ぶ勉強会 Kubernetes Internal #3 の補足資料を意図して執筆されました。本文中で参照しているソースコードのバージョンは v1.19.4 です。
スケジューラの概要
ソースコードを読むに先立つ予備知識として、スケジューリングの大まかな流れと Scheduling Framework の概要に触れておきます。
スケジューリングの流れ
ReplicaSet や Job によって作成されたばかりの Pod は、配置先の Node が未定の状態になっています。この Node を決定するのが kube-scheduler の役割であり、さらにその結果を各 Node で稼働している kubelet が見て、自 Node に割り当てられた Pod を実際に立ち上げる、というのが Kubernetes の動作原理です。
配置先が決まっていない Pod がキューに格納されていると考えてください。kube-scheduler のメイン部分は以下のように動作します。
- Pod を一つ、キューから取り出す
- 取り出した Pod が配置できる可能性がある Node をフィルタリングする
- 可能性のある Node のうち最も良いものを選ぶ
- API Server 経由で Bind リソースを作成する
1 から 3 までをスケジューリングサイクル、4 をバインディングサイクルと呼びます。スケジューリングサイクルは直列化されており常に Pod を一つずつ扱いますが、バインディングサイクルは Pod ごとに goroutine 上で実行されます。スケジューリングサイクルは 3 で Node が確定してバインディングサイクルの goroutine を起動させたあと、完了を待たずに次の Pod のスケジュールサイクルを開始します。
なお、2 で条件にあった Node のみフィルタリングする際、場合によっては一つも残らないことがあります。このような場合に Kubernetes は、 その Pod よりも Priority が低い稼働中 Pod を削除することで Node に空きを作ろうとします。この手続きを Preemption と呼びます。

Scheduler Extender
上で述べた流れに対して、追加ロジックを差し込むことができる機構が用意されています。あらかじめ kube-scheduler に設定を加えておくとスケジューリングの特定のポイントで HTTP リクエストが外部サーバに送信され、それにレスポンスすることで kube-scheduler の挙動を変えることができます。
拡張できるのは以下の 4 点です。
- Filter: Node をフィルタリングした結果を受け取り、さらに候補を絞る
- Prioritize: Node を選択する際の優先度付け関数を追加する
- Bind: バインディングサイクル内で追加で他の処理を行う
- Preempt: Preemption で犠牲となる予定の Pod を受け取り、その中に削除されたくない Pod があれば外す
Scheduling Framework
Extender を利用したスケジューリングロジックのカスタマイズには、いくつか問題点が指摘されていました。
まず単純に拡張点が少なく、カスタマイズの余地に制限があること。また、外部サーバに JSON Webhook を投げるという実装上パフォーマンスが落ちること。さらに、Webhook サーバが外部にあることで、拡張点をまたいだ情報の受け渡しやエラー時のハンドリングがスケジューラ側ではコントロールできないこと。
さらに kube-scheduler の実装自体も種々の拡張により肥大化が進んでおり、外部で新たなカスタムスケジューラを実装しようとするとかなりの部分が kube-scheduler の再実装にならざるを得ませんでした。
この問題に対して、コントロールフロー部分だけを提供しロジックを差し替えたスケジューラを作成できるようにする仕組みが Scheduling Framework です。Scheduling Framework では、以下の拡張点を定義しています。
- スケジューリング待ちキューに作用するもの
- QueueSort: 優先度付きキューの優先度関数を変更する
- フィルタリングに作用するもの
- PreFilter
- FIlter
- スコアリングに作用するもの
- PreScore
- Score
- NormalieScore
- バインドに作用するもの
- Reserve: バインド前に Node や Volume などの確保をキャッシュに登録する
- Permit: バインディングサイクルの先頭で Pod を一旦待機させる
- PreBind
- Bind
- PostBind
今回のコードリーディングでは、これらの拡張点がどのように実装されているかも含め、スケジューリングの流れを追いつつ確認していきます。

プラグインの実装
Scheduling Framework のプラグインは、Name を返す Plugin interface の他、各拡張点に対応した interface を実装している必要があります。以下は Pod を配置できる可能性がある Node をフィルタリングする Filter プラグインの interface です。
type FilterPlugin interface { Plugin Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status }
あらかじめ実装が提供されている Scheduling Framework のプラグインは pkg/scheduler/framework/plugins に配置されています。
各プラグインは一般には複数個の拡張点をサポートしています。例えば pkg/scheduling/framework/plugins/node_affinity.go にある NodeAffinity プラグインは Filter と Score の両方のメソッドを実装しており、両方の拡張点での挙動に影響を与えます。
var _ framework.FilterPlugin = &NodeAffinity{} var _ framework.ScorePlugin = &NodeAffinity{}
また、上に示した Filter を見て取れるように、プラグインのメソッドは *CycleState を引数に取ります。この CycleState は排他制御付きの map であり、複数の拡張点やプラグインの間でデータを共有するために使用できます。ただし、CycleState はその名の通り、スケジューリングサイクルが開始されるごとにリセットされるため、データが共有できるのはあくまでも一つの Pod のスケジューリング内です。
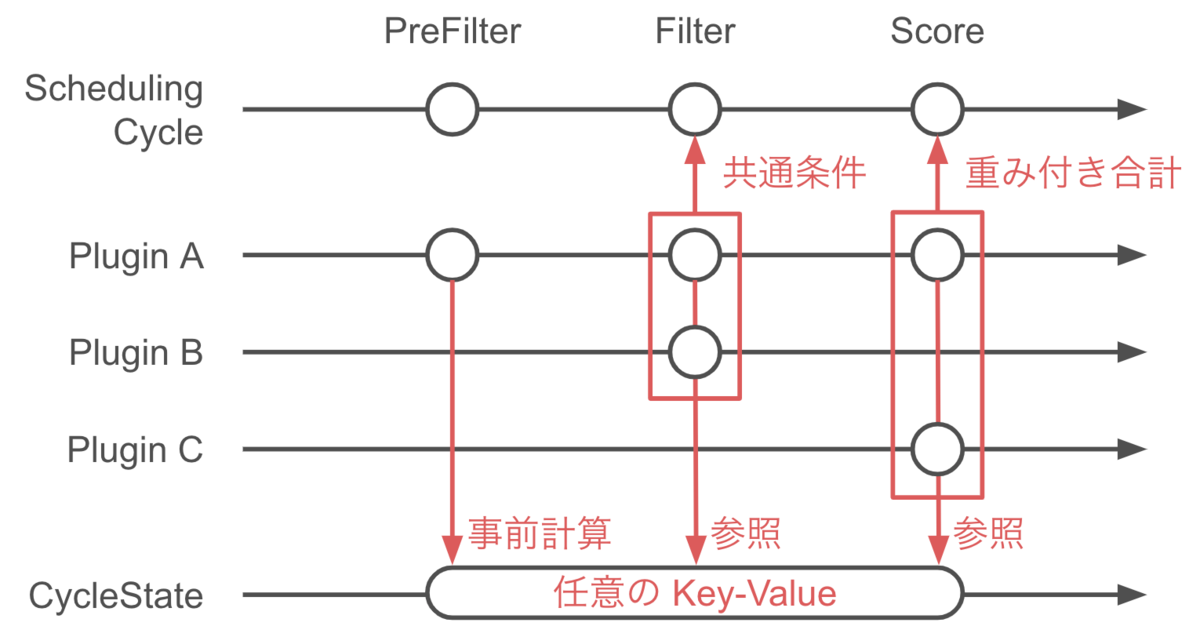
スケジューリングサイクルの実装
スケジューリングサイクルの本体は pkg/scheduler/scheduler.go で実装されています。kube-scheduler は実行されると SchedulingQueue を起動させた上で、scheduleOne の無限ループに入ります。
func (sched *Scheduler) Run(ctx context.Context) { if !cache.WaitForCacheSync(ctx.Done(), sched.scheduledPodsHasSynced) { return } sched.SchedulingQueue.Run() wait.UntilWithContext(ctx, sched.scheduleOne, 0) sched.SchedulingQueue.Close() }
この scheduleOne こそがスケジューラのロジックのコア部分であり、前述したスケジューリングの流れにほぼそのまま対応しています。以下、実装にい沿って詳細を見ていきましょう。
Pod の取り出し
冒頭、NextPod によりスケジューリングの対象となる Pod をキューからひとつ取り出します。後述しますが、このキューは Pod の Priority による優先度付きキューとして振る舞います。
podInfo := sched.NextPod()
次に、profileForPod で取り出した Pod に対応する Scheduling Profile を取得してどのようなロジックを採用するのかを決めます。また、削除中であったり、すでに配置先が決まっていた Node を再度見つけた場合は skipPodUpdate(pod) でスキップし、何も行いません。
pod := podInfo.Pod prof, err := sched.profileForPod(pod) (snip) if sched.skipPodSchedule(prof, pod) { return }
最後に、スケジューリングサイクルを始めるにあたって、プラグインのデータ置き場である CycleState をリセットしておきます。
state := framework.NewCycleState()
配置先 Node の決定
先に概要として述べた通りmPod を配置する Node を決定するにあたっては、
- 候補となる Node を絞る
- 残った Node に優先度をつける
- 一番優先度の高い Node を選択する
という手続きが行われます。これら一連の動作は pkg/scheduler/core/generic_scheduler.go で定義された Schedule メソッドで行われます。
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, prof, state, pod)
この中で、上記の「候補となる Node を絞る」を行うのが findNodesThatFitPod、「残った Node に優先度をつける」を行うのが prioritizeNodes、「一番優先度の高い Node を選択する」を行うのが selectHost です。
feasibleNodes, filteredNodesStatuses, err := g.findNodesThatFitPod(ctx, prof, state, pod)
priorityList, err := g.prioritizeNodes(ctx, prof, state, pod, feasibleNodes)
host, err := g.selectHost(priorityList)
Node のフィルタリング
ではさらに findNodesThatFitPod の中身を確認していきます。まず、PreFilter プラグインが呼び出されます。
s := prof.RunPreFilterPlugins(ctx, state, pod)
そして実際に Node をフィルタリングする処理はさらに二つの処理からなります。
まず一段階目は Filter プラグインによる findNodesThatFitPod です。
feasibleNodes, err := g.findNodesThatPassFilters(ctx, prof, state, pod, filteredNodesStatuses)
findNodesThatFitPod の内部では、各 Node に対して Pod との相性が並行してチェックされるようになっています。checkNode がチェックする処理で、さらにその内部で呼ばれている PodPassesFiltersOnNode が実際に Filter プラグインを呼び出す部分になっています。
parallelize.Until(ctx, len(allNodes), checkNode)
checkNode := func(i int) { // We check the nodes starting from where we left off in the previous scheduling cycle, // this is to make sure all nodes have the same chance of being examined across pods. nodeInfo := allNodes[(g.nextStartNodeIndex+i)%len(allNodes)] fits, status, err := PodPassesFiltersOnNode(ctx, prof.PreemptHandle(), state, pod, nodeInfo) //(snip) }
冒頭でも提示しましたが、Filter プラグインは Filter メソッドにより定義される interface になっています。PodPassesFiltersOnNode の内部では RunFilterPlugin が実行されており、これが各プラグインの Filter 結果を統合して一つでも失敗した Node は候補から外される仕組みになっています。処理の本体は pkg/scheduler/framework/runtime/framework.go にあります。
また、二段階目の findNodesThatPassExtenders では Extender による判定が行われます。
feasibleNodes, err = g.findNodesThatPassExtenders(pod, feasibleNodes, filteredNodesStatuses)
もし、この段階で候補となる Node が見つからなかった場合は、Preemotion の手続きに進みます。ここでは一旦、一つ以上の Node が見つかったとして話を続けましょう。
Node のスコアリング
prioritizeNodes でフィルタリングの結果生き残った Node に優先順序をつけます。Filter のときと同じく、ここでもまず PreScore プラグインが呼び出されます。
preScoreStatus := prof.RunPreScorePlugins(ctx, state, pod, nodes)
そしてやはり Filter の時と同じく、スコアリングもプラグインによるものと Extender によるものを合わせて考えます。まず、Score プラグインによるスコアの算出です。プラグイン名とそのプラグインによる Node の採点結果が map になって返されます。NormalizeScore プラグインによる正規化もここで行われます。
scoresMap, scoreStatus := prof.RunScorePlugins(ctx, state, pod, nodes)
そして、この結果に Extender によるスコアを足し込みます。Extender が複数登録されている場合、各 Extender ごとに並行して計算されます。
for i := range g.extenders { // (snip) go func(extIndex int) { // (snip) prioritizedList, weight, err := g.extenders[extIndex].Prioritize(pod, nodes) mu.Lock() for i := range *prioritizedList { host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score // (snip) combinedScores[host] += score * weight } mu.Unlock() }(i) }
なお、プラグインによるスコアと Extender によるスコアの合算の際にはスケール調整を行っています。
result[i].Score += combinedScores[result[i].Name] * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority)
Node の選択
最後に、selectHost が Node ごとのスコアの結果 priorityList を受け取って Node を一つ選択します。selectHost の中身は単純にループを回して最大値を選択する(同点の場合はランダム)だけです。
host, err := g.selectHost(priorityList)
バインディングサイクルの実装
Pod の配置先 Node が決定したあと、実際に Pod の Status を書き換えて配置を行う操作は Pod ごとに goroutine を発行することで行われます。これは、Volume のプロビジョニングの待ち時間や後述の CoScheduling によって Pod がすぐに起動できない場合であっても、先に次の Pod のスケジューリングサイクルを開始するためです。
まず、処理が goroutine として分岐する前に、Reserve プラグインと Permit プラグインが呼び出されます。
if sts := prof.RunReservePlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {...}
runPermitStatus := prof.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
この次、Permit プラグインの呼び出しが終わったあとの処理を見ると、goroutine で無名関数を実行していることがわかります。
go func() { bindingCycleCtx, cancel := context.WithCancel(ctx) defer cancel() // (snip) }()
この goroutine の中で最初に実行されるのが WaitOnPermit です。Permit プラグインによって許可が行われるまで Pod は待機状態になります。goroutine として分岐した後なので、ここで Pod が待たされている間も後続の Pod は次のスケジューリングサイクルに入ることができます。
waitOnPermitStatus := prof.WaitOnPermit(bindingCycleCtx, assumedPod)
Pod が待機状態から解放されると、まず PreBInd プラグインが呼び出されます。
preBindStatus := prof.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
そして実際のバインド処理は bind が実行されます。bind の中身は Filter や Score と同じくプラグインと Extender の両方が使用されますが、今回は Extender の実行が先で、かつその時点でバインドが成功すればプラグインには処理が渡らないようになっています。
func (sched *Scheduler) bind(ctx context.Context, prof *profile.Profile, assumed *v1.Pod, targetNode string, state *framework.CycleState) (err error) { // (snip) bound, err := sched.extendersBinding(assumed, targetNode) if bound { return err } bindStatus := prof.RunBindPlugins(ctx, state, assumed, targetNode) // (snip) }
最後に PostBind プラグインを呼び出して一連の処理が終了です。
prof.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
なお、Reserve プラグイン呼び出し後の Volume 操作やプラグイン呼び出しでエラーが発生した場合、Reserve を取り消す必要があります。そのため、各エラーハンドリング内では Reserve プラグインを呼び出して取り消し処理を行うようになっています。
prof.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
Preemption
ここまで、最初のフィルタリングの段階で少なくとも一つの Node が見つかった場合の流れについて解説してきました。しかし実際の運用中には必ずしも候補となる Node が存在するとは限りません。
では、条件に合う Node が全く見つからなかった場合の処理も見ていきましょう。このとき Schedule が FitError を返すことにより Preemption の手続きが開始されます。
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, prof, state, pod) if err != nil { nominatedNode := "" if fitError, ok := err.(*core.FitError); ok { if !prof.HasPostFilterPlugins() { klog.V(3).Infof("No PostFilter plugins are registered, so no preemption will be performed.") } else { // Run PostFilter plugins to try to make the pod schedulable in a future scheduling cycle. result, status := prof.RunPostFilterPlugins(ctx, state, pod, fitError.FilteredNodesStatuses) if status.IsSuccess() && result != nil { nominatedNode = result.NominatedNodeName } } // (snip) }
ここで、nominatedNode には、Preemption の結果 Pod が立ち退かされて空きができた Node の名前が記録されます。ただし、最終的に Pod がこの nominatedNode に配置されるとは限りません。再度スケジューリングサイクルを通過する間に他の Pod に埋められてしまう可能性もあり得ます。
Preemption 処理のロジックは PostFilter プラグインが担当します。
result, status := prof.RunPostFilterPlugins(ctx, state, pod, fitError.FilteredNodesStatuses)
デフォルトの状態では PostFilter は DefaultPreemption プラグインのみが実装しています。 ソースコードは pkg/scheduler/framework/plugins/default/preemption/default_preemption.go です。
処理の本体は preempt メソッドであり、以下の処理が行われます。
- そもそもその Pod が Preempt 対象かどうか調べる
- 削除できる可能性のある Pod をリストアップする
- Extender に問い合わせて除外すべき Node がないかどうか調べる
- もっとも影響が軽い Node を選択する
- 実際に Pod を削除する
ロジックの中心となっているのは「候補となる Node をリストアップする」を行う selectVictimsOnNode です。大まかに
- まず、各 Node 上で、考えている Pod より Priority が低い Pod を全部削除した状態を考える
- そこから Pod を一つづつ戻してみる。PodDisruptionBudget に影響される Pod を優先して戻す
- それ以上戻せない、すなわち新しい Pod を配置するために必要な最低限の犠牲がどの Pod になるかを調べる
という順序で処理が行われます。
参考文献
過去のスライド
公式ドキュメント
まとめ
Kubernetes において、Pod を配置するための Node を選択する手続きをスケジューリングと呼びます。本記事では、デフォルトのスケジューラである kube-scheduler のソースコードを追うことで、Node がどのように選択されるのかの内部アルゴリズムを解説しました。特に最新の kube-scheduler では、Scheduling Framework を用いることでアルゴリズム中のロジックを差し替え可能になっているのが特徴です。
なお、今回大きくは扱いませんでしたが、運用上スケジューラのパフォーマンスに大きく影響する仕組みとして、スケジューリングキューとキャッシュが挙げられます。いつか機会があればこれらのトピックについても解説したいと思いますが、それはまた別の話。