July Tech Festa 2021 winter で CockroachDB と TLA+ について話してきました
こんにちは、チェシャ猫です。
インフラ技術のカンファレンス July Tech Festa 2021 winter で、形式手法ツール TLA+ が CockroachDB の設計に使用された事例について発表してきました。公募 CFP 枠です。
今回の登壇は、昨年の CloudNative Days Tokyo 2020 と同じ題材を扱っています。ただ、前回より持ち時間が長くなった分、前回のスライドで説明不足だった部分を拡充してあります。特に、CockroachDB 以外の TLA+ 採用事例や、分散システムにおける Chaos Engineering の位置付けについて解説を追加しました。
なお、前回の登壇報告は以下の記事をご参照ください。
当日出た質問
実時間を含む性質
今回の時相論理では「いつか成り立つ」という性質を記述していたが、時間制限をつけて「n 分以内に成り立つ」いう記述は可能ですか?
いいえ、TLA+ では「何らかの条件 B が成り立つより前に A が成り立つ」という記述はできますが、「n 分以内」のような実際の時間に言及するような記述はサポートしていません。
ただ TLA+ 以外だとこのような性質を記述・検査できるツールも存在します。実時間モデル検査と呼ばれる分野で、有名なツールとしては商用製品ですが UPPAAL が挙げられます。スライド中で「ベースとする数学的対象によってツールの性質が変わる」という話を出しましたが、UPPAAL は時間オートマトン (Timed Automata) をベースにしています。
事例の詳細
その他の TLA+ 採用事例についてもう少し具体的に知りたいです
スライド中に挙げた事例については、以下のリンクが参考になると思います。
AWS DynamoDB
Azure Cosmos DB
TiDB / TiKV
Elasticsearch
学習リソース
形式手法の勉強をしようとすると情報が少なくて困るのですが、TLA+ を勉強する際に良い資料はありますか?
本家である Lamport が自身の Web ページ上にチュートリアルを公開しています。ご本人による動画による解説付きです。やや題材が硬派というか地味な感じですが、TLA+ の機能は最もしっかり解説されているように思います。
また、とりあえず動かしてみて雰囲気を掴みたいということであれば、以下のチュートリアルサイトも小綺麗で良い感じです。このサイトの作者 Hillel Wayne はCockroach Lab 社で TLA+ のセミナーを開催したとのことで、まさに今回の CockroachDB の事例のきっかけを作った人物です。
まとめ
以上、簡単ではありますが、July Tech Festa 2021 winter での登壇と、当日出た質問についてまとめました。
なお、今回の講演で解説した内容は、説明を簡略化するために実際の仕組みを省略している部分がいくつか存在します。もしオリジナル版に興味がある方は、GitHub で公開されている TLA+ 仕様記述を読み解いてみるのも面白いでしょう。
ところで、講演中に OSS の事例として挙げた TiDB と Elasticsearch は、「TLA+ だけでなく他の手法と組み合わせて検証を行なっている」という点でも興味深いプロジェクトです。TiDB が Chaos Mesh を開発していることはスライドに述べた通り、また Elasticsearch は Isablle というまた毛色の違う形式手法ツールを併用しています。
今回 CockroachDB を扱ったので、他のプロジェクトについてもいつかメインで取り上げたいと思っていますが、それはまた別の話。
Kubernetes: kube-scheduler をソースコードレベルで理解する
はじめに
Kubernetes において、Pod を配置するための Node を決定する手続きをスケジューリングと呼び、デフォルトのクラスタでは kube-scheduler がその責務を担っています。本記事ではこの kube-scheduler のソースコードを時系列に沿って追いつつ、どのようなロジックで Pod を配置する Node が決定されるのかを解説します。
なお、本記事は Kubernetes の内部実装について学ぶ勉強会 Kubernetes Internal #3 の補足資料を意図して執筆されました。本文中で参照しているソースコードのバージョンは v1.19.4 です。
スケジューラの概要
ソースコードを読むに先立つ予備知識として、スケジューリングの大まかな流れと Scheduling Framework の概要に触れておきます。
スケジューリングの流れ
ReplicaSet や Job によって作成されたばかりの Pod は、配置先の Node が未定の状態になっています。この Node を決定するのが kube-scheduler の役割であり、さらにその結果を各 Node で稼働している kubelet が見て、自 Node に割り当てられた Pod を実際に立ち上げる、というのが Kubernetes の動作原理です。
配置先が決まっていない Pod がキューに格納されていると考えてください。kube-scheduler のメイン部分は以下のように動作します。
- Pod を一つ、キューから取り出す
- 取り出した Pod が配置できる可能性がある Node をフィルタリングする
- 可能性のある Node のうち最も良いものを選ぶ
- API Server 経由で Bind リソースを作成する
1 から 3 までをスケジューリングサイクル、4 をバインディングサイクルと呼びます。スケジューリングサイクルは直列化されており常に Pod を一つずつ扱いますが、バインディングサイクルは Pod ごとに goroutine 上で実行されます。スケジューリングサイクルは 3 で Node が確定してバインディングサイクルの goroutine を起動させたあと、完了を待たずに次の Pod のスケジュールサイクルを開始します。
なお、2 で条件にあった Node のみフィルタリングする際、場合によっては一つも残らないことがあります。このような場合に Kubernetes は、 その Pod よりも Priority が低い稼働中 Pod を削除することで Node に空きを作ろうとします。この手続きを Preemption と呼びます。

Scheduler Extender
上で述べた流れに対して、追加ロジックを差し込むことができる機構が用意されています。あらかじめ kube-scheduler に設定を加えておくとスケジューリングの特定のポイントで HTTP リクエストが外部サーバに送信され、それにレスポンスすることで kube-scheduler の挙動を変えることができます。
拡張できるのは以下の 4 点です。
- Filter: Node をフィルタリングした結果を受け取り、さらに候補を絞る
- Prioritize: Node を選択する際の優先度付け関数を追加する
- Bind: バインディングサイクル内で追加で他の処理を行う
- Preempt: Preemption で犠牲となる予定の Pod を受け取り、その中に削除されたくない Pod があれば外す
Scheduling Framework
Extender を利用したスケジューリングロジックのカスタマイズには、いくつか問題点が指摘されていました。
まず単純に拡張点が少なく、カスタマイズの余地に制限があること。また、外部サーバに JSON Webhook を投げるという実装上パフォーマンスが落ちること。さらに、Webhook サーバが外部にあることで、拡張点をまたいだ情報の受け渡しやエラー時のハンドリングがスケジューラ側ではコントロールできないこと。
さらに kube-scheduler の実装自体も種々の拡張により肥大化が進んでおり、外部で新たなカスタムスケジューラを実装しようとするとかなりの部分が kube-scheduler の再実装にならざるを得ませんでした。
この問題に対して、コントロールフロー部分だけを提供しロジックを差し替えたスケジューラを作成できるようにする仕組みが Scheduling Framework です。Scheduling Framework では、以下の拡張点を定義しています。
- スケジューリング待ちキューに作用するもの
- QueueSort: 優先度付きキューの優先度関数を変更する
- フィルタリングに作用するもの
- PreFilter
- FIlter
- スコアリングに作用するもの
- PreScore
- Score
- NormalieScore
- バインドに作用するもの
- Reserve: バインド前に Node や Volume などの確保をキャッシュに登録する
- Permit: バインディングサイクルの先頭で Pod を一旦待機させる
- PreBind
- Bind
- PostBind
今回のコードリーディングでは、これらの拡張点がどのように実装されているかも含め、スケジューリングの流れを追いつつ確認していきます。

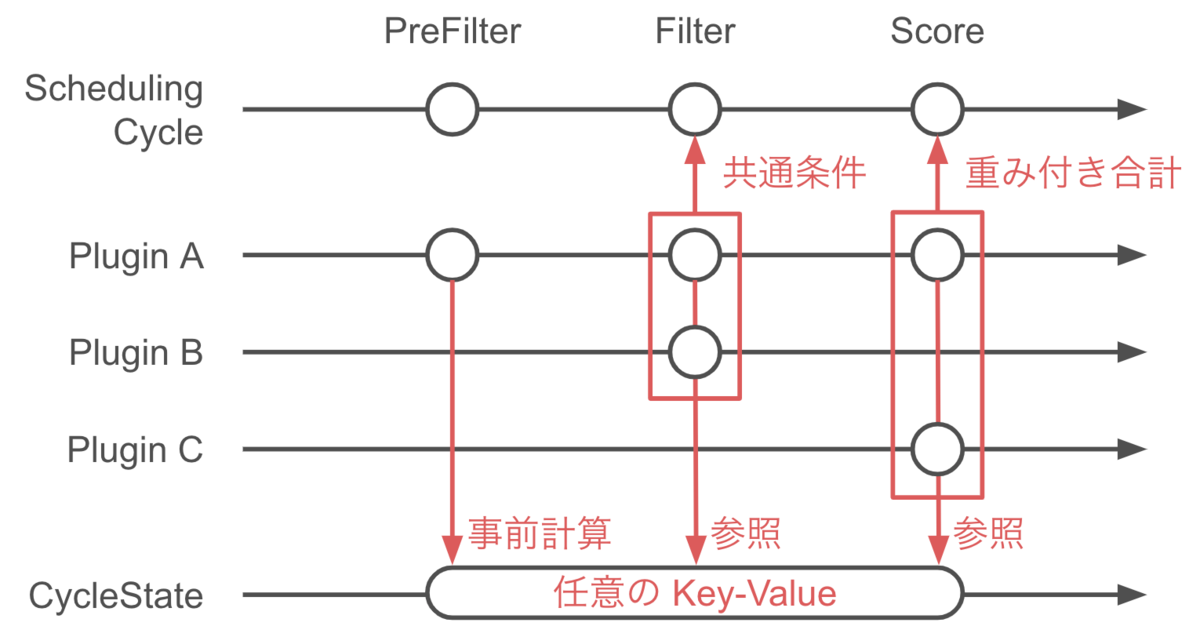
プラグインの実装
Scheduling Framework のプラグインは、Name を返す Plugin interface の他、各拡張点に対応した interface を実装している必要があります。以下は Pod を配置できる可能性がある Node をフィルタリングする Filter プラグインの interface です。
type FilterPlugin interface { Plugin Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status }
あらかじめ実装が提供されている Scheduling Framework のプラグインは pkg/scheduler/framework/plugins に配置されています。
各プラグインは一般には複数個の拡張点をサポートしています。例えば pkg/scheduling/framework/plugins/node_affinity.go にある NodeAffinity プラグインは Filter と Score の両方のメソッドを実装しており、両方の拡張点での挙動に影響を与えます。
var _ framework.FilterPlugin = &NodeAffinity{} var _ framework.ScorePlugin = &NodeAffinity{}
また、上に示した Filter を見て取れるように、プラグインのメソッドは *CycleState を引数に取ります。この CycleState は排他制御付きの map であり、複数の拡張点やプラグインの間でデータを共有するために使用できます。ただし、CycleState はその名の通り、スケジューリングサイクルが開始されるごとにリセットされるため、データが共有できるのはあくまでも一つの Pod のスケジューリング内です。
スケジューリングサイクルの実装
スケジューリングサイクルの本体は pkg/scheduler/scheduler.go で実装されています。kube-scheduler は実行されると SchedulingQueue を起動させた上で、scheduleOne の無限ループに入ります。
func (sched *Scheduler) Run(ctx context.Context) { if !cache.WaitForCacheSync(ctx.Done(), sched.scheduledPodsHasSynced) { return } sched.SchedulingQueue.Run() wait.UntilWithContext(ctx, sched.scheduleOne, 0) sched.SchedulingQueue.Close() }
この scheduleOne こそがスケジューラのロジックのコア部分であり、前述したスケジューリングの流れにほぼそのまま対応しています。以下、実装にい沿って詳細を見ていきましょう。
Pod の取り出し
冒頭、NextPod によりスケジューリングの対象となる Pod をキューからひとつ取り出します。後述しますが、このキューは Pod の Priority による優先度付きキューとして振る舞います。
podInfo := sched.NextPod()
次に、profileForPod で取り出した Pod に対応する Scheduling Profile を取得してどのようなロジックを採用するのかを決めます。また、削除中であったり、すでに配置先が決まっていた Node を再度見つけた場合は skipPodUpdate(pod) でスキップし、何も行いません。
pod := podInfo.Pod prof, err := sched.profileForPod(pod) (snip) if sched.skipPodSchedule(prof, pod) { return }
最後に、スケジューリングサイクルを始めるにあたって、プラグインのデータ置き場である CycleState をリセットしておきます。
state := framework.NewCycleState()
配置先 Node の決定
先に概要として述べた通りmPod を配置する Node を決定するにあたっては、
- 候補となる Node を絞る
- 残った Node に優先度をつける
- 一番優先度の高い Node を選択する
という手続きが行われます。これら一連の動作は pkg/scheduler/core/generic_scheduler.go で定義された Schedule メソッドで行われます。
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, prof, state, pod)
この中で、上記の「候補となる Node を絞る」を行うのが findNodesThatFitPod、「残った Node に優先度をつける」を行うのが prioritizeNodes、「一番優先度の高い Node を選択する」を行うのが selectHost です。
feasibleNodes, filteredNodesStatuses, err := g.findNodesThatFitPod(ctx, prof, state, pod)
priorityList, err := g.prioritizeNodes(ctx, prof, state, pod, feasibleNodes)
host, err := g.selectHost(priorityList)
Node のフィルタリング
ではさらに findNodesThatFitPod の中身を確認していきます。まず、PreFilter プラグインが呼び出されます。
s := prof.RunPreFilterPlugins(ctx, state, pod)
そして実際に Node をフィルタリングする処理はさらに二つの処理からなります。
まず一段階目は Filter プラグインによる findNodesThatFitPod です。
feasibleNodes, err := g.findNodesThatPassFilters(ctx, prof, state, pod, filteredNodesStatuses)
findNodesThatFitPod の内部では、各 Node に対して Pod との相性が並行してチェックされるようになっています。checkNode がチェックする処理で、さらにその内部で呼ばれている PodPassesFiltersOnNode が実際に Filter プラグインを呼び出す部分になっています。
parallelize.Until(ctx, len(allNodes), checkNode)
checkNode := func(i int) { // We check the nodes starting from where we left off in the previous scheduling cycle, // this is to make sure all nodes have the same chance of being examined across pods. nodeInfo := allNodes[(g.nextStartNodeIndex+i)%len(allNodes)] fits, status, err := PodPassesFiltersOnNode(ctx, prof.PreemptHandle(), state, pod, nodeInfo) //(snip) }
冒頭でも提示しましたが、Filter プラグインは Filter メソッドにより定義される interface になっています。PodPassesFiltersOnNode の内部では RunFilterPlugin が実行されており、これが各プラグインの Filter 結果を統合して一つでも失敗した Node は候補から外される仕組みになっています。処理の本体は pkg/scheduler/framework/runtime/framework.go にあります。
また、二段階目の findNodesThatPassExtenders では Extender による判定が行われます。
feasibleNodes, err = g.findNodesThatPassExtenders(pod, feasibleNodes, filteredNodesStatuses)
もし、この段階で候補となる Node が見つからなかった場合は、Preemotion の手続きに進みます。ここでは一旦、一つ以上の Node が見つかったとして話を続けましょう。
Node のスコアリング
prioritizeNodes でフィルタリングの結果生き残った Node に優先順序をつけます。Filter のときと同じく、ここでもまず PreScore プラグインが呼び出されます。
preScoreStatus := prof.RunPreScorePlugins(ctx, state, pod, nodes)
そしてやはり Filter の時と同じく、スコアリングもプラグインによるものと Extender によるものを合わせて考えます。まず、Score プラグインによるスコアの算出です。プラグイン名とそのプラグインによる Node の採点結果が map になって返されます。NormalizeScore プラグインによる正規化もここで行われます。
scoresMap, scoreStatus := prof.RunScorePlugins(ctx, state, pod, nodes)
そして、この結果に Extender によるスコアを足し込みます。Extender が複数登録されている場合、各 Extender ごとに並行して計算されます。
for i := range g.extenders { // (snip) go func(extIndex int) { // (snip) prioritizedList, weight, err := g.extenders[extIndex].Prioritize(pod, nodes) mu.Lock() for i := range *prioritizedList { host, score := (*prioritizedList)[i].Host, (*prioritizedList)[i].Score // (snip) combinedScores[host] += score * weight } mu.Unlock() }(i) }
なお、プラグインによるスコアと Extender によるスコアの合算の際にはスケール調整を行っています。
result[i].Score += combinedScores[result[i].Name] * (framework.MaxNodeScore / extenderv1.MaxExtenderPriority)
Node の選択
最後に、selectHost が Node ごとのスコアの結果 priorityList を受け取って Node を一つ選択します。selectHost の中身は単純にループを回して最大値を選択する(同点の場合はランダム)だけです。
host, err := g.selectHost(priorityList)
バインディングサイクルの実装
Pod の配置先 Node が決定したあと、実際に Pod の Status を書き換えて配置を行う操作は Pod ごとに goroutine を発行することで行われます。これは、Volume のプロビジョニングの待ち時間や後述の CoScheduling によって Pod がすぐに起動できない場合であっても、先に次の Pod のスケジューリングサイクルを開始するためです。
まず、処理が goroutine として分岐する前に、Reserve プラグインと Permit プラグインが呼び出されます。
if sts := prof.RunReservePlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost); !sts.IsSuccess() {...}
runPermitStatus := prof.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
この次、Permit プラグインの呼び出しが終わったあとの処理を見ると、goroutine で無名関数を実行していることがわかります。
go func() { bindingCycleCtx, cancel := context.WithCancel(ctx) defer cancel() // (snip) }()
この goroutine の中で最初に実行されるのが WaitOnPermit です。Permit プラグインによって許可が行われるまで Pod は待機状態になります。goroutine として分岐した後なので、ここで Pod が待たされている間も後続の Pod は次のスケジューリングサイクルに入ることができます。
waitOnPermitStatus := prof.WaitOnPermit(bindingCycleCtx, assumedPod)
Pod が待機状態から解放されると、まず PreBInd プラグインが呼び出されます。
preBindStatus := prof.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
そして実際のバインド処理は bind が実行されます。bind の中身は Filter や Score と同じくプラグインと Extender の両方が使用されますが、今回は Extender の実行が先で、かつその時点でバインドが成功すればプラグインには処理が渡らないようになっています。
func (sched *Scheduler) bind(ctx context.Context, prof *profile.Profile, assumed *v1.Pod, targetNode string, state *framework.CycleState) (err error) { // (snip) bound, err := sched.extendersBinding(assumed, targetNode) if bound { return err } bindStatus := prof.RunBindPlugins(ctx, state, assumed, targetNode) // (snip) }
最後に PostBind プラグインを呼び出して一連の処理が終了です。
prof.RunPostBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
なお、Reserve プラグイン呼び出し後の Volume 操作やプラグイン呼び出しでエラーが発生した場合、Reserve を取り消す必要があります。そのため、各エラーハンドリング内では Reserve プラグインを呼び出して取り消し処理を行うようになっています。
prof.RunReservePluginsUnreserve(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)
Preemption
ここまで、最初のフィルタリングの段階で少なくとも一つの Node が見つかった場合の流れについて解説してきました。しかし実際の運用中には必ずしも候補となる Node が存在するとは限りません。
では、条件に合う Node が全く見つからなかった場合の処理も見ていきましょう。このとき Schedule が FitError を返すことにより Preemption の手続きが開始されます。
scheduleResult, err := sched.Algorithm.Schedule(schedulingCycleCtx, prof, state, pod) if err != nil { nominatedNode := "" if fitError, ok := err.(*core.FitError); ok { if !prof.HasPostFilterPlugins() { klog.V(3).Infof("No PostFilter plugins are registered, so no preemption will be performed.") } else { // Run PostFilter plugins to try to make the pod schedulable in a future scheduling cycle. result, status := prof.RunPostFilterPlugins(ctx, state, pod, fitError.FilteredNodesStatuses) if status.IsSuccess() && result != nil { nominatedNode = result.NominatedNodeName } } // (snip) }
ここで、nominatedNode には、Preemption の結果 Pod が立ち退かされて空きができた Node の名前が記録されます。ただし、最終的に Pod がこの nominatedNode に配置されるとは限りません。再度スケジューリングサイクルを通過する間に他の Pod に埋められてしまう可能性もあり得ます。
Preemption 処理のロジックは PostFilter プラグインが担当します。
result, status := prof.RunPostFilterPlugins(ctx, state, pod, fitError.FilteredNodesStatuses)
デフォルトの状態では PostFilter は DefaultPreemption プラグインのみが実装しています。 ソースコードは pkg/scheduler/framework/plugins/default/preemption/default_preemption.go です。
処理の本体は preempt メソッドであり、以下の処理が行われます。
- そもそもその Pod が Preempt 対象かどうか調べる
- 削除できる可能性のある Pod をリストアップする
- Extender に問い合わせて除外すべき Node がないかどうか調べる
- もっとも影響が軽い Node を選択する
- 実際に Pod を削除する
ロジックの中心となっているのは「候補となる Node をリストアップする」を行う selectVictimsOnNode です。大まかに
- まず、各 Node 上で、考えている Pod より Priority が低い Pod を全部削除した状態を考える
- そこから Pod を一つづつ戻してみる。PodDisruptionBudget に影響される Pod を優先して戻す
- それ以上戻せない、すなわち新しい Pod を配置するために必要な最低限の犠牲がどの Pod になるかを調べる
という順序で処理が行われます。
参考文献
過去のスライド
公式ドキュメント
まとめ
Kubernetes において、Pod を配置するための Node を選択する手続きをスケジューリングと呼びます。本記事では、デフォルトのスケジューラである kube-scheduler のソースコードを追うことで、Node がどのように選択されるのかの内部アルゴリズムを解説しました。特に最新の kube-scheduler では、Scheduling Framework を用いることでアルゴリズム中のロジックを差し替え可能になっているのが特徴です。
なお、今回大きくは扱いませんでしたが、運用上スケジューラのパフォーマンスに大きく影響する仕組みとして、スケジューリングキューとキャッシュが挙げられます。いつか機会があればこれらのトピックについても解説したいと思いますが、それはまた別の話。
安全性-活性分解定理とその関連研究
こんにちは、チェシャ猫です。先日行われた第 7 回 Web System Architecture 研究会で形式手法について発表してきました。
普段、形式手法について登壇する際は具体例な検証例を出すことが多いですが、今回は理論側に寄せたサーベイになっています。
はじめに
本セッションでは、安全性-活性分解 (safety-liveness decomposition) と呼ばれる一連の結果について解説する。安全性-活性分解は、システムの仕様が与えられた時、それを安全性 (safety) および活性 (liveness) と呼ばれる、よりシンプルな特徴付けを持つクラスに分解して扱うための方法論である。さらにセッションの後半では、安全性と活性の組み合わせ以外にも提案されている派生的な特徴付けについても述べる。
Web アプリケーションと形式手法
システムやプログラムの性質を何らかの数学的な対象を通して表現、検証する方法論を形式手法 (formal methods) と呼ぶ。
期待される入力と出力を人間が具体的に与える従来のテストと比較し、形式手法では理論的な背景に基づいた抜けや漏れのない検証が可能であり、また並行性のようなコントロールが困難な性質についても網羅的な検証を行うことができる。また、実装に依存せず設計段階でその意図を表現・検証できるというメリットもある。一方、形式手法を扱えるプログラマは多くなく、また一般には記述コストが通常のテストに比べて高くなるというデメリットも存在する。
伝統的には形式手法は、例えば航空宇宙関連の組み込みプログラムのような、高コストを支払ってでもそれを上回る信頼性が必要となる分野で用いられてきた。しかし近年では分散システムが身近になったことに起因し、Web アプリケーション開発において形式手法が採用される事例も見られる。一例としてここでは Amazon Web Service による S3 および DynamoDB のレプリケーションを検証した事例 [CRZ15]、および CockroachDB の分散トランザクションの最適化を検証した事例 [TSM20] を挙げておく。
安全性と活性
システムやプログラムの仕様を表現するにあたって、安全性と活性の二種類の仕様があることは古くから経験的に知られてきた。非形式的な表現で述べるなら、安全性とは「何か悪いことが決して起こらない性質」であり、活性とは「何か良いことがいつかは起こる性質」である。
シンプルな例として排他制御を考える。二つのプロセスが並行して動作し、各々が実行中にクリティカルセクションに入る必要があるとする。直感的にイメージされる性質は「二つのプロセスが同時にクリティカルセクションに入ることがない」であり、これは安全性に属する性質である。
しかし実はこの記述には不足があり、システムとして要求される性質を完全には表現していない。各プロセスが一度もクリティカルセッションに入らないようなシステムであってもこの安全性を満たすからである。したがって「各プロセスが実行中にいずれクリティカルプロセスに入る」という条件が必要であり、これが活性に相当する。
このことからもわかる通り、システムに要求される性質を記述する上では、安全性だけでなく活性を与えることが本質的に必要である。
分解定理
システムを検証するに当たって、前提としてその動作や期待する性質を何らかの形で記述する必要がある。停止するプログラムであれば入力-出力の関係としてその性質を記述することも考えられるが、システムサーバのような動き続けるシステムを記述するにはこの形式は不向きである。
このような場合、システムの状態を要素とする無限列を考えることが一般的である。例えば、システムに関与する各プロセスのプログラムカウンタの位置と各変数に代入された値の組はそのシステムの状態とみなすことができる。状態の無限列をパス (path) あるいは振る舞い (behaviour)と呼び、パス全体がなす集合の部分集合を性質 (property) と呼ぶ。
ここで、パスの定義は「実際にそのシステムが動作中に実現しうるもの」に限られない点に注意されたい。最終的な目標となる「システムが要求された性質を満たすことの検証」とはすなわち、「パスのうちシステムが実現しうるもの集合が要求したい性質の集合に含まれていること」に他ならない。
二つのパスに対して「最初 n 個目までの状態までが一致する」という関係はパス間の距離を定義する。したがって、パス全体の集合に対して、この距離が誘導する位相構造を考えることができる。
Alpern と Schneider [AS85] はこの位相構造を用いて、安全性と活性にエレガントな定義を与えている。特に活性については、これが最初の理論的な定義である。
定義:閉な部分集合を安全性 (safety property)、稠密な部分集合を活性 (liveness property) と呼ぶ
非形式的な表現に直すなら、安全性とは「要求に違反する無限列があったとしたら最初の有限個の状態ですでに違反している」性質であり、活性とは「最初の有限個がどんな状態であっても、その後続をうまく取れば全体としては要求を満たすことができる」性質である。これは前項で述べた安全性および活性の直感的な理解とよく一致する。
ところで、一般に位相空間において、任意の集合は閉集合と稠密集合の共通部分として表現することができる。このことから以下の定理が従うことがわかる [AS85]。
定理:任意の性質
に対して、安全性
と活性
が存在して
言い換えれば、システムに要求される任意の性質は、安全性に属する部分と活性に属する部分に分解できることがわかる。この定理は分解定理あるいは Alpern-Schneider 型定理と呼ばれ、以降に述べるような様々な派生的な研究のきっかけとなっている。

サブクラスに対する分解
上に示した分解定理は、任意の性質 に対して成立するという意味では適用範囲が広いが、具体的に性質を記述したり判定を行ったりする目的には向かない。実用上はより具体的な記述の形式や分解の手続きが必要である。さらに、分解した結果を効率的に運用するためには、あるクラスに属する性質を分解した結果もそのクラスに閉じていること望ましい。ここでは知られている例として、Büchi オートマトンに対する結果および線形時相論理式に対する結果を取り上げる。
Büchi オートマトンに対する分解
Büchi オートマトンは有限状態オートマトンのある意味での拡張である。有限状態オートマトンが正規言語に対応するように、Büchi オートマトンは ω-正則言語と呼ばれる記号列のクラスに対応する。有限状態オートマトンを用いて記号の有限列が条件にマッチするかどうかを定義できるのと同様、Büchi オートマトンは与えられた記号の無限列が条件にマッチするかどうかを定義する。
非形式的な表現で述べれば、有限の記号列がある有限状態オートマトンに受理されるとは、記号に応じてオートマトンの遷移を辿っていった際、最終状態が受理状態であることを指す。これに対して無限の記号列がある Büchi オートマトンに受理されるとは、記号に応じてオートマトンの遷移を辿っていった際、受理状態を無限回通過することを指す。
今、考えているシステムのパスとは状態の無限列のことであり、システムの性質とはパス全体がなす集合の部分集合であった。つまり記号の集合として状態の集合を考えると、Büchi オートマトン に対して
が受理するパスの集合
が定まり、これは何らかの性質を定義しているとみなすことができる。
Alpern と Schneider は先ほどの抽象的な分解に加えて、与えられた Büchi オートマトン から二つの Büchi オートマトン
と
を構成する手続きを示した [AS87]。
定理:任意の既約 Büchi オートマトン
に対して、
および
はそれぞれ安全性と活性となる。さらに
が成り立つ
この定理は先に述べた位相を利用して得られる定理と同様、性質を安全性と活性とに分解する記述を与えている。ただしその分解の対象は性質の中でも特に Büchi オートマトンにより定義できるものに限られ、その代わり分解のための具体的な手続きを提供する。
線形時相論理式に対する分解
線形時相論理 (linear temporal logic, LTL) は、時相論理と呼ばれる時間的な広がりを持った条件を記述することができる諸体系の一部である。 時相論理には複数のクラスがあり、LTL の他にも計算木論理 (computational tree logic, CTL) や、LTL と CTL の両者を内包する CTL* などの体系が知られている。木構造の分岐を扱うことができる CTL に対して、時間発展を直線的なモデル、すなわち状態列として扱うのが LTL の特徴である。
一般に時相論理おける論理式は、単一の状態に対する通常の命題論理に時相論理用の演算子を追加して記述される。どの記号がどの位置に出現することを許すかによって時相論理の中でも上記のバリエーションが生まれるが、LTL として妥当な演算子とその非形式的な意味は以下の二つである。
:次の状態で
が成立する
:今後いつかは
が成立し、かつそれまでの間は
が成立する
実用上の文脈では、これらの演算子を用いてさらに定義される
が使用されることが多い。非形式的には は「今後、いつかは
が成立する」 、
は「今後、常に
が成立する」といったような意味になる。
LTL 論理式は無限列に対してその真偽が判定できるため、やはり何らかの性質を表現しているとみなすことができる。Maretić らはこの LTL で表される性質のクラスに対する結果として以下を示した [MDB14]。前述の Büchi オートマトンに関する結果と同じく、与えられた性質を安全性と活性に分解する形式になっている。
定理:任意の LTL 論理式
に対して、安全性を表現する LTL 論理式
と活性を表現する LTL 論理式
が存在して
なお、LTL 論理式で表現できる性質は Büchi オートマトンでも表現できるが、逆は成り立たない。LTL 論理式の表現力は Büchi オートマトンの中でも特に counter-free と呼ばれるクラスに属しているものに等しく [DG08]、これは Büchi オートマトン全体より真に狭い [W83]。つまり LTL 論理式に対する上記の定理は、LTL 論理式が分解について閉じていることを意味している。
性質に対する分類の拡張
ここまでに述べてきた結果は、対象とする性質のクラスに差はあるが、いずれも Alpern-Schneider により定式化された安全性と活性という分類に基づいたものであった。やや方向性が異なる研究として、従来とは異なる新たな分類手法を提案した文献を二つ取り上げる。
束論を用いた特徴付け
束 に対して、以下の条件を満たす作用素
を閉包作用素と呼ぶ。
ならば
ある集合が与えられた時、その部分集合の全体に包含関係で順序を入れたものは束になり、位相の意味での閉包を取る操作は閉包作用素の条件を満たす。このため、位相を用いて定義された安全性と活性の概念は、束を用いて再定義することができる。
Manolios と Trefler はこの着想に基づき、束上で定義される安全性と活性の類似物について論じている [MR03]。具体的には以下のような定義である。
定義:可補モジュラー束
上の閉包演算子
が与えられたとする。
を満たすような元
を
-安全性 (
を満たすような元
を
として位相的な閉包を取る操作を考えると、これらの定義は先に挙げたものの一般化になっている。さらにこの方針の面白い性質は、分解された各部分を特徴づける際に共通の
を用いる必要がないという事実である。以下の定理からわかるように、特定の条件下さえ満たされれば、安全性と活性の定義に異なる
を使用することができる。
定理:
と
を可補モジュラー束
に対して
が成り立つとする。このとき
-安全性
と
が存在して
が成り立つ
この一般化を利用して論文中では、分岐時間的 (branching-time) な性質、すなわちここまで見てきたような状態の直線的な無限列ではなく、状態をノードとするような木構造に対して定義された性質についても、従来と類似の分解定理が成立することが示されている。
定理:任意の分岐時間的な性質は、existentially safe な性質と existentially live な性質の共通部分、universally safe な性質と universally live の共通部分、existentially safe な性質と universally live な性質の共通部分、のすべてのパターンに分解可能である
ここで existentially および universally の具体的な定義は省略するが、それぞれ別の閉包作用素を通じて定義される性質である。非形式的な表現でいえば、状態がなす木構造において、existentially safe は「うまいルートの辿り方をすれば悪いことが起こらない」性質、universally safe は「どんなルートを辿ったとしても悪いことが起こらない」性質といった意味になる。
分岐時間的な分解定理は先に挙げた束上の分解定理の直接的な系であり が existentially、
が universally に対応している。universally safe と existentially live の組み合わせだけが抜けているのは条件
が満たされないためであり、実際にこの組み合わせでは分解できない反例が存在する。
またこの分岐時間の例は、束論による定義が位相による定義の真の拡張になっていることを示す例でもある。実際、universally を定義する閉包作用素は位相的な意味でも閉包を与えるが、existantially を定義する閉包作用素は位相的な意味では閉包にはならない。
階層的な特徴付け
また別の観点からの定式化を用いたシステムの性質の分類として、Chang らによる研究が知られている [CMP93]。従来の Alpern-Schneider 型の研究では性質を安全性と活性に二分していたが、Chang らは階層的なモデルを提案している。
既に述べた通り、Alpern と Schneider による分類は閉集合を安全性、稠密集合を活性とするものであった。Chang らの論文中では複数の視点から同値な定義が与えられているが、対応がわかりやすいように位相による定義を用いて彼らの分類を述べると以下のようになる。
定義:閉集合、開集合、加算個の閉集合の和、加算個の開集合の共通部分として特徴付けられるクラスをそれぞれ Safety、Guarantee、Response、Persistence と呼ぶ
さらに、副次的なクラスとして Safety と Guarantee の両方に属するクラスを Obligation、Response と Persistence の両方に属するクラスを Reactivity として定義している。
面白いのは、理論的に自然な階層として定義されたこれらの性質と、システムに求められる要件の階層がよく対応しているように見えることである。例えば Persistence を定義する「加算個の開集合の共通部分」というクラスは、 とも表され集合論では古くからよく知られた研究対象であるが、これは非形式的な表現では「いつかは成立し、かつ一度成立するとその後は成立したままになる」という状況に対応している。
なお、Chang らによる Safety の定義は Alpern-Schendier 型の安全性と共通しているが、他のクラスは活性とは直行する概念である。実際、Guarantee、Obligation、Response、Persistence、Reactivity のいずれかを で表すと、以下の分解定理が成立する。
定理:クラス
に属する任意の性質
に対して、Safety に属する
と
が存在して
参考文献
[AS85] B. Alpern, and F. B. Schneider. 1985. “Defining Liveness.” Information Processing Letters 21 (4): 181–85.
[AS87] B. Alpern, and F. B. Schneider. 1987. “Recognizing Safety and Liveness.” Distributed Computing 2 (3): 117–26.
[CMP93] E. Chang, Z. Manna, and A. Pnueli. 1993. “The Safety-Progress Classification.” In Logic and Algebra of Specification, 143–202. Springer Berlin Heidelberg.
[CRZ15] N. Chris, T. Rath, F. Zhang, B. Munteanu, M. Brooker, and M. Deardeuff. 2015. “How Amazon Web Services Uses Formal Methods.” Communications of the ACM 58 (4): 66–73.
[DG08] V. Diekert, and P. Gastin. 2008. “First-Order Definable Languages.” Logic and Automata 2: 261–306.
[MR03] P. Manolios, and R. Trefler. 2003. “A Lattice-Theoretic Characterization of Safety and Liveness.” In Proceedings of the Twenty-Second Annual Symposium on Principles of Distributed Computing, 325–33. PODC ’03. New York, NY, USA: Association for Computing Machinery.
[MDB14] G. P. Maretić, M. T. Dashti, and D. Basin. 2014. “LTL Is Closed under Topological Closure.” Information Processing Letters 114 (8): 408–13.
[TSM20] R. Taft, I. Sharif, A. Matei, N. VanBenschoten, J. Lewis, T. Grieger, K. Niemi, et al. 2020. “CockroachDB: The Resilient Geo-Distributed SQL Database.” In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, 1493–1509. SIGMOD ’20. New York, NY, USA: Association for Computing Machinery.
[W83] P. Wolper. 1983. “Temporal Logic Can Be More Expressive.” Information and Control 56 (1): 72–99.
CloudNative Days Tokyo 2020 で CockroachDB と TLA+ について話してきました
こんにちは、チェシャ猫です。先日行われた CloudNative Days Tokyo 2020 で、形式手法ツール TLA+ が CockroachDB の設計に使用された事例について発表してきました。公募 CFP 枠です。
講演概要
CockroachDB は、Google Spanner の系譜に連なるいわゆる NewSQL データベースの一種です。
強い一貫性や ACID トランザクションといった従来の関係データベースが持つ「良い特徴」を残したまま、従来の関係データベースが苦手としていた水平スケーリングにも優れるのが特徴です。CockroachDB 自身は「地理分散 (geo-distributed) データベース」を標榜しています。
このような CockroachDB の特徴は、内部のデータ保持の方法に由来します。データは内部的には Key-Value レコードの形を取っていて、データ全体を一定のサイズで Range と呼ばれる単位に区切った上で、Range ごとに Raft 合意アルゴリズムを用いて Node 間複製を行います。
異なる Range 間では Raft による一貫性ははたらきません。したがって、複数の Key に対して同時に捜査する SQL をサポートするためには、分散トランザクションが必要になります。
当初の CockroachDB のトランザクションは、クライアントがトランザクションの完了通知を受け取るまでに Raft による合意のレイテンシが 2 往復分必要でした。新しく導入された Parallel Commit はこのレイテンシを減らし、1 往復で完了通知が出せるようにしたものです。
ところで、一般に分散アルゴリズムを正しく設計するのは難しい作業です。一般に複数のプロセスはそれぞれのタイミングで処理を進めており、実行順について正確に予測することができません。また、分散システムではプロセス間通信がネットワークを挟むため、パケットの遅延・入れ替わり・消失などについて全ての場合を考える必要があります。
結果として、非常に限られたパターンでしか発現しないバグが含まれていたとしても、それを通常のテストを通して発見するのは極めて困難です。
CockroachDB の Parallel Commit プロトコルも例外ではありません。そこで Cockroach Lab はこのプロトコルの正しさを検証するために形式手法 (formal methods)を利用しました。
形式手法は、対象となるシステムを数学的な定式化を用いて厳密に記述し、その性質を検査する方法群です。中でも今回利用されたツールは TLA+ と呼ばれるもので、CockroachDB 以外にも、Cosmos DB や TiDB など CloudNative として名前が挙がる OSS で使用されています。
Parallel Commit の具体的なプロトコル、および TLA+ による検査の内容について詳細はスライドを参照してください。
Parallel Commit に関する補足
講演中に解説した Parallel Commit の動作は簡略化されたものであり、説明のためにいくつかの要素が意図して省かれています。
Pipelining
今回の解説では、トランザクションに属するすべてのキーとトランザクションレコード自体を同時に書き込む形式になっていました。しかし実際には COMMIT コマンドが発行されるよりも前、すなわちトランザクションに含まれるキーが確定しないうちに Intent の書き込みリクエストが始まります。この最適化は Pipelining と呼ばれています。
この挙動は TLA+ の記述にも反映されており、キー確定前にリクエストを送信する pipelined_keys と、確定後にトランザクションと同時にリクエストを送信する parallel_keys が分けて扱われています。
Timestamp Cache と Epoch
今回の解説では、Transaction Recovery の途中でコンフリクトするインテントを発見し次第 Abort させる形式になっていました。このとき実際には、未達だった書き込みリクエストが Abort 後になって到着して書き込まれることがないよう、「Intent が存在しないことが観測された時刻」を Timestamp Cache として保持しておきます。また、書き込むとき Timesatmp Cache を悲観的にチェックした上で、衝突が発生した場合にはトランザクションの Epoch を増やして最初からやり直す処理が必要です。
この挙動も TLA+ の記述に反映されており、インテントを扱う際には tscache を確認する仕組みになっています。
参考資料
CockroachDB
- CockroachDB: Distributed SQL - Cockroach Labs
- How CockroachDB Does Distributed, Atomic Transactions | Cockroach Labs
- Parallel Commits: An Atomic Commit Protocol For Globally Distributed Transactions | Cockroach Labs
- RFC: Paralell Commit
- TLA+ in CockroachDB
TLA+
その他 TLA+ 事例
まとめ
今回の講演では、分散データベース CockroachDB のアーキテクチャを概説したのち、合意レイテンシを減らす最適化 Parallel Commit の必要性について述べました。また Parallel Commit の検証において、形式手法の一種 TLA+ が使われている様子について例を挙げて説明しました。
ところで、実は CockroachDB の TLA+ 仕様には正しくない部分があり、しかしそのミスは通常の検査では Transaction Recovery で覆い隠されてしまうため、非常に見つけにくい状態になっています。
チェシャ猫自身が今回の講演の準備中に気づいたので既に Issue として挙げておいたのですが、これをどうやって発見したのか、それはまた別の話。
【#CODT2020 解説】Infrastructure as Code の静的テスト戦略
こんにちは、チェシャ猫です。先日行われた Cloud Operator Days Tokyo 2020 で、Infrastructure as Code のテストについて発表してきました。公募 CFP 枠です。
Cloud Operator Days Tokyo 2020 は今回が初開催のイベントですが、昨年 CloudNative Days Tokyo と併設されていた OpenStack Days Tokyo が前身となっているようです。
今年は OpenStack に限らず広く運用がテーマにされていますが、セッションのラインナップを見る限り、他のイベントよりもオンプレミス・エンタープライズ的な色が強く出ているように感じられます。
ちなみに、チェシャ猫の発表は事前アンケートで割と人気があったようで、以下のプレスリリースでは 7 位につけています。どこの現場も、Infrastructure as Code を現実の方法論として取り込みつつやっぱり辛さも感じている、というぐらいのフェイズなのかもしれません。

{kind=link}
目指したかったこと
今回発表するにあたって、自分の中の隠しテーマとして
- 誰でも体感的には感じていることを自分なりの定式化で語る
という目標を設定していました。
普段チェシャ猫が登壇する際には、その場にいる人が知らないであろう新奇な情報の提供を狙っていることが多いです。例えばそれは Kubernetes のリリースされたばかりのアルファ機能や内部的な挙動に関する Deep Dive であったり、形式手法のような一般に馴染みの薄い要素技術だったりします。
それに対して今回の登壇では、技術的に目新しい情報はほとんど含んでいません。しかしもちろんご存知の通り、IaC について書かれた既存の資料はスライド冒頭にも出した O'Reilly 本をはじめとして山のように存在するわけで、どこかでスピーカーの独自色を出す必要があります。
そこで「予測可能性」というワードを中心に据えて、「IaC に対して静的テストを考える必然性」にどれだけ説得力を持たせられるか、という観点でプレゼンを組み立ててみました。
幸いにしてこの狙いはある程度成功したようで、Serverspec の作者 mizzy 氏からも以下のようなコメントを頂いています。
チェシャ猫さんの発表にあった、IaC関連ツールをLocal/Global, Mutable/Immutable の四象限にわける考え方、とても良いな、と思いました。 #CODT2020
— Gosuke Miyashita (mizzy) (@gosukenator) 2020年7月29日
予測可能性の3要素、再現性、純粋性、モジュール性という考え方も参考になりました。冪等性ではなく純粋性、という考え方も。 #CODT2020
— Gosuke Miyashita (mizzy) (@gosukenator) 2020年7月29日
当日お話しした内容
以下、スライドの内容を追いつつ必要に応じて参考リンクを挙げていきます。
IaC における「静的」テスト
IaC は死せども IaC は永遠なれ
ここ数年、Infrastructure as Code はもはや特別なものではなく、誰もが存在は知っているし、少なくとも部分的には実践しているであろう共通認識の一部になりました。前述の mizzy 氏も、Infra Study Meetup #1 の基調講演において「IaC is dead. Long live IaC」という言い回しでそのことを表現しています。

あなたの「辛さ」はどこから?
しかしいざ IaC を導入してみると、謳われているほど意外と楽にはならず、むしろ「IaC 疲れ」みたいな状態になってしまうというのはよく聞く話です。この辛さはなぜ、どのように発生するのか?
そもそも、ひとことで IaC と言っても人によってそのイメージは様々で意外と統一されていません。そこで本セッションではまず「今回考えたい IaC とは何か」を定義することにしました。

O'Reilly 本では IaC を 4 領域に分類していますが、少なくともチェシャ猫の感覚だと、この分類は「辛さ」に対する説明力があまり高いようには思えませんでした。今回対策を立てるべき「辛くなりやすい領域」を明確化するため、本セッションでは「Local / Global」「Mutable / Immutable」を軸とした 4 象限で分類しています。
Local / Global が影響範囲による分類で、
- Local:変更の影響範囲が特定のリソース内で閉じる(例えばサーバ内の設定ファイルを変更して再起動)
- Global:変更がインフラ全体の広範囲にわたって影響する(例えばネットワークの設計や被依存性の高いリソースの変更)
Mutable / Immutable は更新方式による分類です
- Mutable:既に存在するリソースに対して更新を重ねていく方式
- Immutable:変更の際には一度削除して再作成する方式
より「モダンで素性の良いインフラ」は、コンポーネント間が疎に結合され、かつ変更時にはゼロから再作成する形式になっていることが多いように思います。上の分類で言えば Local + Immutable の枠ですね。逆に言えばこの対極である Global + Mutable の領域には「辛さ」が凝縮しがちです。
塩漬けインフラ負のサイクル
この「辛さ」の凝縮を説明するのが次の図です。

インフラの設計や運用に無理が出てしまうと、IaC をデプロイした時の影響範囲が読めなくなり、それによって余計に IaC への移行が阻害されるため余計に無理が出る、という典型的な構図で、O'Reilly 本では「オートメーション恐怖症」という言葉で表現されています。
ではそのサイクルをどこで防止するかと言えば「影響範囲が読めるようにすればよい」ということになり、ここから本セッションのテーマである予測可能性を究極のゴールとして据えることができます。

ちなみにこの「予測可能性」というワーディングは、Haskeller である igrep 氏の記事から着想を得ています。
デプロイの壁と静的テスト
そもそも同じ「ソースコードによる管理」を行なっているにも関わらず、インフラがアプリより辛くなりがちな気がするのはなぜでしょう? それを考えるのが以下のスライドです。

アプリケーションの特にウォーターフォールモデルの開発において、開発と品質保証とのの関係を説明するために V 字モデルがよく取り上げられます。これをインフラに移し変えて考えてみると、デプロイ以前にテストする手段に乏しいこと気づくでしょう。Serverspec や awsspec のようなツールはありますが、これはいずれも「既にデプロイされたサーバをテストするもの」であって、「デプロイの壁」の向こう側にあるものです。
インフラにおいて「デプロイの壁」はアプリ以上に深刻です。それは金銭的コストの問題かもしれないし、社内統制の問題かもしれないし、あるいは部署間の組織的ハードルかもしれません。しかし何れにせよ、「新しくインフラを作成する」というのは「既にあるインフラにアプリをデプロイする」ことと比較して桁違いのコストを伴います。
以上が、今回のセッションで「Global + Mutable 領域のツールに対して、デプロイ前のテストを重視すること」に着目する動機付けです。

AWS における予測可能性
では具体的に AWS で IaC を実践しようとしたとき、予測可能性はどのような要件として現れるでしょうか? 本セッションではそれを「再現性」「純粋性」「モジュール性」という三つの要素としてまとめました。

IaC の文脈ではよく「冪等性」という言葉が使用されます。二度繰り返してデプロイしても最初と結果が変わらないことですね。しかしここでは予測可能性について考える上で、必要なのはむしろ「純粋性」である、という立場をとりました。
IaC のデプロイをある種の関数であると考えると、その引数は「IaC ツールに与えるテンプレートやパラメータ 」および「現在のインフラの状況
」であり、戻り値は「更新後のインフラの状況
」です。数式で表すなら
のような形になるでしょう。この記法を用いると、冪等性と純粋性はそれぞれ以下で表される性質です。
- 冪等性:任意の
に対して
- 純粋性:任意の
に対して
この定義から、純粋性において と取れば冪等性が得られるため、純粋性の方が冪等性より強い性質であることがわかります。
ちなみにテスタビリティを担保する上での純粋性という用語は、Haskell をはじめとする関数型プログラミング言語から着想を得たものです。
AWS リソース管理のステップ
実際に AWS 上のリソースを作成する方法としては、ナイーブなものから高度なものまで、以下の 4 段階を辿って発展するモデルを想定しました。
- マネジメントコンソールから手作業で作成
- AWS CLI を使用してシェルスクリプト 化
- CloudFormation により宣言的な YAML を記述
- Cloud Development Kit (CDK) で YAML を生成
このような流れで CDK 登場の経緯を説明する手法には前例があり、例えば以下の Black Belt Seminar も同様のストーリーで解説されています。
本セッションではそれに加えて、テーマとして掲げた「予測可能性のための三要素」がどのように反映されているか、という観点から各手法の比較を行っています。

なお、この後のプレゼンでお見せした CDK のソースコードは、以下の公式チュートリアルの TypeScript 版をほぼ引用しています。CDK は TypeScript の他 Python、Java、.NET が使用できますが、後述のテスト関係の Jest 統合など、TypeScript が最も機能的に充実している印象です。
CDK に対するテストツール
CDK は作成したコンポーネント = Consutuct をテストするためのフレームワークが付属しています。元々は CDK 自体の開発の中で使用するために開発されたものですが、ユーザである我々が自作コンポーネントの出来をテストすることも可能です。
ドキュメント等では、テストは三種類に分類されています。ただし、内容を見てもらえればわかる通り、Validation は単なる TypeScript の例外系テストであって CDK 由来の特殊性はありません。
- Snapshot Test:CDK から CloudFormation への生成結果が
test/__snapshot__に保存され、次回 CDK 変更時に回帰テストを行うことができる - Fine-grained Assertion:ライブラリ
@aws-cdk/assertが提供されていて、CloudFormation の生成結果に関して属性ベースのアサーションが記述できる - Validation Test:Construct の生成時の変数(= Props)に与える値のバリデーションができる
このうち Fine-grained Assertion と Validation については先述の公式チュートリアルに記述があります。Snapshot Test については解説がないので、以下のドキュメントを合わせて読むと良いでしょう。
テスト戦略とツール
さて、CDK にはテストがあるからこれで十分かと言えば全くそんなことはありません。CDK のテストはあくまでも「CDK に対するテスト」であって、そのデプロイ結果が意図した挙動を示すかというのはまた別の手段で保証する必要があります。言葉を変えれば、CDK に備わっているテストは
生の CloudFormation と比較して、CDK を経由することで導入された非自明性を補償するもの
であると考えることができます。つまり生の CloudFormation を書く限りにおいてリソースの設定値は「そこに書いてある」以上のものではないわけですが、CDK を使用することで生成過程が隠蔽されてしまうため、その隠蔽の過程で何か意図しない変換が起こっていないかをテストしているわけです。
これを図式的に示したものが以下のスライドです。結局のところ、当初の問題であった予測可能性の担保、すなわち「デプロイしたら動かない」を防ぐためには、「YAML をデプロイした結果」についてデプロイ前にテストする必要があります。

本セッションでは、ツールとして cfn-nag、CloudFormation Guard および Conftest を紹介しました。
チュートリアルに沿って実装していくと、この時点ですでに cdk.out ディレクトリ内に CloudFormation に渡される JSON が作成されているはずなのでこれを検査対象とします。もし見当たらない場合には cdk synth コマンドを実行すると生成されます。
cfn-nag
cfn-nag はセキュリティ系ルールにフォーカスした検査ツールです。ベストプラクティスに沿った定義済みルールが多数用意されており、細かくカスタムルールを定義する前にとりあえずデフォルトで実行してみるといった使い方が可能です。
cfn-nag の実装は Ruby なので gem コマンド、あるいは Mac であれば brew コマンドで直接インストールすることも可能ですが、今回は Docker イメージとして配布されているものを使用してみます。
$ docker run --rm -v `pwd`/cdk.out:/tmp/cdk.out stelligent/cfn_nag /tmp/cdk.out/CdkWorkshopStack.teplate.json ------------------------------------------------------------ /tmp/cdk.out/CdkWorkshopStack.template.json ------------------------------------------------------------------------------------------------------------------------ | WARN W68 | | Resources: ["EndpointDeployment318525DA5f8cdfe532107839d82cbce31f859259"] | Line Numbers: [286] | | AWS::ApiGateway::Deployment resources should be associated with an AWS::ApiGateway::UsagePlan. ------------------------------------------------------------ (snip...) ------------------------------------------------------------ | WARN W58 | | Resources: ["HelloHandler2E4FBA4D", "HelloHitCounterHitCounterHandlerDAEA7B37"] | Line Numbers: [38, 157] | | Lambda functions require permission to write CloudWatch Logs Failures count: 0 Warnings count: 9
意外と多数の警告が出ました。cfn-nag はあらかじめ定義されているルールの豊富さがメリットですが、現実の開発ですべてのルールが必ずしも有効とは限りません。特に開発環境では、コストや便宜性との兼ね合いにより、意図的にセキュリティ上のチェックを無効化する必要がしばしば生じます。
例として、今出た警告をすべて抑制してみましょう。policy/blacklist.yaml として以下のファイルを保存しておきます。
--- RulesToSuppress: - id: W58 reason: global blacklist example - id: W59 reason: global blacklist example - id: W64 reason: global blacklist example - id: W68 reason: global blacklist example - id: W69 reason: global blacklist example - id: W73 reason: global blacklist example - id: W74 reason: global blacklist example
このファイルを -b または --blacklist-path オプションに与えることで、該当するナンバーのエラーや警告が検知されなくなります。
$ docker run --rm -v `pwd`:/tmp/cdk-workshop stelligent/cfn_nag /tmp/cdk-workshop/cdk.out/CdkWorkshopStack.template.json -b /tmp/cdk-workshop/policy/blacklist.yaml ------------------------------------------------------------ /tmp/cdk-workshop/cdk.out/CdkWorkshopStack.template.json ------------------------------------------------------------ Failures count: 0 Warnings count: 0
CloudFormation Guard
CloudFormation Guard はこの 6 月に新しくリリースされたツールです。こちらはセキュリティに限らず、ユーザが自由にルールを定義して使用することが想定されています。
ルールの記述は、基本的には個々のプロパティの値をチェックする形式で書くことになります。等号・不等号による比較の他、配列に含まれているかどうかのチェックやワイルドカードや正規表現の使用も可能です。可読性を上げるための変数も定義できます。
ただ、CloudFormation Guard はまだリリースから間もないこともあり、使い勝手の面はあまり整備されていません。今の段階で実戦投入は難しいのではないかという印象ですが、今後に期待しましょう。
Conftest
Conftest は、Rego と呼ばれる Prolog 派生の論理型言語を使用した検査ツールです。
もともと Conftest は、CNCF プロジェクトの一つである Open Policy Agent (OPA) から派生したツールです。OPA は CNCF が出自だけあり、Kubernetes コミュニティでの利用が盛り上がっており、最近ではカンファレンス等で実戦投入した事例も散見されます。OPA を直接使用するというよりは、Kubernetes の Admission Webhook と統合された Gatekeepr として導入されることが多いようです。
そこで Conftest の位置付けとしては、この Gatekeeper と共通の Rego による記述を採用することで、CI 上でも Admission Webhook と同様の検査を行うことを指向しています。なお Kubernetes の Manifest の検査に Conftest 使う例については、tkusumi 氏による以下の記事を読むとよいでしょう。
さて、Conftest の用途は Kubernetes に限ったものではなく、一般に YAML や JSON、あるいは Hashicorp 製品のための設定言語である HCL も検査の対象とすることが可能です。今回は CDK から出力されたテンプレートに Conftest を使用してみます。
まず、前述のチュートリアルを実行してエラーが出るところまで進めていると仮定します。ここまでの実装には、続く解説にも述べられている通り、
- カウンタ用の Lambda Function から DynamoDB への読み込み・書き込み権限がない
- カウンタ用の Lambda Function から後続の Hello World 用 Lambda Function を呼び出す権限がない
の二種類の不足点がありますが、ここでは例として前者を検知します。
Conftest は特に指定しない場合、policy ディレクトリ内の Rego ファイルを読みます。policy/mypolicy.rego として以下を保存してください。
package main
deny[msg] {
rs := input.Resources
functions := [ [name, rs[name] ] | rs[name].Type = "AWS::Lambda::Function" ]
tables := [ [name, rs[name] ] | rs[name].Type = "AWS::DynamoDB::Table" ]
roles := [ [name, rs[name] ] | rs[name].Type = "AWS::IAM::Role" ]
policies := [ [name, rs[name] ] | rs[name].Type = "AWS::IAM::Policy" ]
violations := [ [f, t] |
f := functions[_];
t := tables[_];
needs_permission(f, t)
not has_permission(f, t, roles, policies)
]
count(violations) > 0
msg := sprintf(
"The function %v cannot access the table %v",
[violations[_][0][0], violations[_][1][0]]
)
}
needs_permission([_, function], [table_name, _]) {
function.Type = "AWS::Lambda::Function"
function.Properties.Environment.Variables["HITS_TABLE_NAME"].Ref = table_name
}
has_permission(f, t, roles, policies) {
r := roles[_]
p := policies[_]
has_role(f, r)
has_policy(r, p)
allows(p, t)
}
has_role([_, function], [role_name, _]) {
function.Type = "AWS::Lambda::Function"
function.Properties.Role["Fn::GetAtt"][0] = role_name
}
has_policy([role_name, _], [_, policy]) {
policy.Type = "AWS::IAM::Policy"
policy.Properties.Roles[_].Ref = role_name
}
allows([_, policy], [table_name, _]) {
policy.Type = "AWS::IAM::Policy"
statements :=
policy.Properties.PolicyDocument.Statement[_]
statements.Effect = "Allow"
statements.Resource[_]["Fn::GetAtt"][0] = table_name
statements.Action[_] = "dynamodb:GetItem"
statements.Action[_] = "dynamodb:PutItem"
statements.Action[_] = "dynamodb:UpdateItem"
}
今回はこのチュートリアルの構成のために特化してルールを書いたためややハードコード気味ではありますが、一つ一つ読み下していけば難しくはありません。Rego のルールは定義の集合として記述され、自然言語で書くなら以下のような内容になっています。
- エラーとは、違反の数が 0 を超えていること
- 違反とは、権限が必要であるにも関わらず保持していない Function
fと Tabletの組が存在すること - Function
fが Tabletに対する権限を必要とするとは、fが環境変数HITS_TABLE_NAMEでtを参照していること - Function
fが Tabletに対する権限を保持しているとは、ある Rolerと Policypの組みが存在し、fがrを持ち、rがpを持ち、pはtへのアクセスを許可していること - Function
fが Rolerを持つとは、fが Role 属性でrを参照していること - Policy
pが Rolerを持つとは、pが Roles 属性でrを参照していること - Policy
pが Tabletへのアクセスを許可しているとは、pの Statement としてtへの Action を Allow していること
個々のルールは単純ですが、組み合わせることで複雑なルールを記述することができます。Rego が持つ単一化の仕組みを利用することで、具体的なリソース名に言及することなく「以下を満たすような f と t の組が存在する」といった条件を探索できることに注目してください。
ちなみに、引数が [policy_name, policy] のようなタプルになっている点に違和感を覚えるかもしれませんが、これはエラーメッセージにリソース名を入れる際に便利だったという便宜的なものです。使わない部分では _ 値で捨てています。
チュートリアルを途中まで実装した状態(すなわち grantReadWriteData が追加されていない状態)で Conftest を実行すると、以下のようにエラーが表示されます。
$ conftest test cdk.out/CdkWorkshopStack.template.json FAIL - cdk.out/CdkWorkshopStack.template.json - The function HelloHitCounterHitCounterHandlerDAEA7B37 cannot access the table HelloHitCounterHits7AAEBF80
そして、チュートリアルに従って CDK 側で権限を追加した後、再度 cdk synth で生成したテンプレートを検査させると、今度はエラーが解消することがわかります。
$ conftest test cdk.out/CdkWorkshopStack.template.json 1 test, 1 passed, 0 warnings, 0 failures
まとめ
以上、Cloud Operator Days Tokyo 2020 での登壇「Infrastructure as Code の静的テスト戦略」について解説と補足資料をまとめました。
今回のセッションでは、誰もが一度は感じたことがある「なぜ IaC は辛くなりがちなのか」という問いに対して「予測可能性」の観点から状況の整理を行い、AWS で IaC を実践する上でのテスト戦略とそのためのツールについて解説しました。特に、Conftest を用いて CloudFormation のテンプレートを検査する部分は、あまり他に類を見ない手法なのではないかと思います。みなさんが現場で感じている「辛さ」を改善するヒントになれば幸いです。
ところで、今回は Rego によるルールは一枚のファイルにまとめて記述しました。この記述をモジュール化して再利用可能にすることも可能なのですが、それはまた別の話。
2019 年のスライド一挙公開、あるいは 2020 年の方針
あけましておめでとうございます。2019 年は大変お世話になりました。2020 年も張り切っていきましょう。
さて、2019 年には結構な回数の外部発表を行いました。これらの発表内容のうち一部は単独のブログ記事としてまとめてありますが、機を逸してしまって記事化されていないものも相当数あります。そこで本記事では、2019 年中に行った発表を一覧としてまとめてみました。
2019 年の活動実績
2019 年の登壇は全部で 19 件でした。うち(先着や抽選ではなく)CFP に応募して採択されたものは 4 件です。
チェシャ猫が普段活動している領域は、Twitter の Bio にも書いてある通り、大きく「Kubernetes」「Haskell」「形式手法」の三つのカテゴリに分かれています。このカテゴリで登壇内容を分類したところ、以下のようになりました。
CloudNative に関わるもの(12 件)
- 猫でもわかる Scheduling Framework
- 君だけの最強 Scheduler を作ろう!
- 明日、業務で使える Scheduler Extender
- 雲の世界の共通語 CloudEvents って何?
- Kubernetes v1.15 の新機能で Preemption を制御せよ
- そのコンテナ、もっと「賢く」置けますよ?【CFP 採択】
- CircleCI + Kind による Kubetentes E2E テスト
- Kind で量産する使い捨て Kubernetes
- 賢く「散らす」ための Topology Spread Constraints
- CloudNative を学ぶにはまず KInd より始めよ
- kube-batch による Gang Scheduling
- 「詰める」と「散らす」の動力学【CFP 採択】
CloudNative 技術に関しては 12 件の発表を行いました。ほとんどが Kubernetes のスケジューリングをテーマにしています。
この分野は勉強が活発に行われており LT の機会も多かったため、LT で単発の新機能を紹介し、長尺の発表ではそれらの諸機能を体系的にまとめて解説する、という構図になっています。特に Kubernetes Meetup Tokyo で顕著ですが、LT の倍率が高いので運頼みになりがちだったりします。
関数型プログラミングに関わるもの(4 件)
- サンプルで学ぶ The Elm Architecture
- GHCJS Miso による Haskell + Firebase 10 分間クッキング
- ライブで学ぶ The Elm Architecture
- GHCJS による Web フロントエンド開発
関数型プログラミングに関しては、Haskell および Elm をテーマとして 2 件ずつ計 4 件の発表を行いました。Haskell の 2 件は AltJS である GHCJS を取り上げているため、Elm も含めて 4 件すべてが Web フロントエンドに関する発表ということになります。
形式手法に関わるもの(2 件)
形式手法に関しては、モデル検査と定理証明それぞれ 1 件ずつの発表を行いました。件数としては少ないですが、両者はいずれも CFP 審査を通過して採択されており、かつ持ち時間もそれぞれ 60 分、45 分と長めの発表です。
関連して、いくつかの会社でモデル検査器のハンズオンを開催しました。ツールとしては Alloy を使用し、2 時間ずつ 2 回、計 4 時間で一通りの使い方を学ぶコースです。内容については Pixiv 社の shimashima さんが記事にしてくださっています。
本来であればもう少しちゃんとパッケージ化して募集するところではありますが、もし今この記事を読んで興味を持った方がいらっしゃいましたら、ぜひご連絡いただければ幸いです。
その他(1 件)
上記のどのカテゴリにも該当しませんが、型による値レベルの制約を TypeScript で実現する話です。強いていうなら関数型プログラミングが近いかもしれません。
2019 年のスライド一覧
猫でもわかる Scheduling Framework
Kubernetes Meetup Tokyo #16 での発表です。
Kubernetes の Scheduler の拡張点をインタフェースとして切り出し、実行速度を保ったままプラガビリティを提供するためのプロジェクト Scheduling Framework について解説しました。
この発表を行った時点ではごく一部しか実装されておらず、まだまだ先が長そうな印象でしたが、最新の v1.17 ではかなり進展し、既存の kube-scheduler の実装を Framework として置き換える作業も進んでいます。
君だけの最強 Scheduler を作ろう!
Docker Meetup Tokyo #28 での発表です。
Kubernetes の Scheduler をカスタマイズするための方法を複数挙げ、それぞれの守備範囲について解説しました。
上で触れた Scheduling Framework の他にも、もともと kube-scheduler に備わっているポリシーの指定方法や、Webhook として実装する Extender についても触れています。
明日、業務で使える Scheduler Extender
Cloud Native Meetup Tokyo #7 での発表です。
これまでと同じく Kubernetes の Scheduler カスタマイズをテーマに据えていますが、この発表では Extender に焦点を絞り、4 箇所あるそれぞれの各頂点でどのような設定が可能なのかについて解説しています。
なお、スライド中で「実行中の Job が Preemption で中断される問題」について言及していますが、後になって Extender 以外にも Preempting を抑制する機能として PreemptingPolicy の設定が導入されました。これについては Docker Meetup Tokyo #31 で触れています。
雲の世界の共通語 CloudEvents って何?
Cloud Native Developer JP #11 での発表です。
Event-driven なアーキテクチャは Serverless 界隈でよくみられますが、その仕様は各ベンダごとにバラバラで相互運用性がありません。この問題を解決するために、イベント仕様の規格策定を目指す CNCF プロジェクト CloudEvents について概要を解説しました。
ちなみに CloudEvents 自体その後も継続してバージョンアップが行われており、Knative や Argo CD などが新しいバージョンに対応しているようです。
サンプルで学ぶ The Elm Architecture
Meguro.es #21 での発表です。なお、上に貼ったスライドは別イベントの際のものですが、内容の大筋は共通しています。
ミニマルなカウンタアプリを例として、The Elm Architecture と呼ばれる状態管理の仕組み、および外部 JavaScript ライブラリとの連携について解説しています。
GHCJS Miso による Haskell + Firebase 10 分間クッキング
Fun Fun Functional #1 での発表です。
GHCJS を使用すると、Haskell のソースコードを JavaScript にコンパイルしてブラウザ上で動かすことができます。この発表ではさらに Elm 風のアーキテクチャを持つフレームワーク Miso および JavaScript 呼び出しのための DSL である JSaddle を使用して、Firebase Realtime DB をバックエンドとした簡単なチャットアプリをライブコーディングで実装しました。
Kubernetes v1.15 の新機能で Preemption を制御せよ
Docker Meetup Tokyo #31 での発表です。
Kubernetes には、Node のリソースに余裕がないときに優先度の高い Pod が作成された場合、すでに稼働している優先度の低い Pod の立ち退かせてリソースを確保する機能が備わっており、この機能は Preemption と呼ばれます。
Preemption はクラスタのリソース効率を高める上では重要ですが、同時に実行中の Job が中断されて途中結果が失われる可能性を含んでいます。この問題を解決するため、v1.15 では Preemption を抑制するための PreemptingPolicy と呼ばれる設定項目が導入されました。
そのコンテナ、もっと「賢く」置けますよ?
CloudNative Days Tokyo 2019 での発表です。
Kubernetes の Scheduler に関して包括的に解説を行なっています。内容としてはそれまでに LT 等で触れたものがほとんどで新規性はありませんが、スケジューラについてあまり知らない人であってもこのスライドの内容を抑えれば一通りの知識が得られるよう、スケジューラの役割から始まって、大枠から徐々に解像度を上げることで学習曲線が緩やかになるように構成が工夫してあります。
CircleCI + Kind による Kubetentes E2E テスト
CircleCI Community Meetup LT 大会 での発表です。
Kind は、Kubernetes の Node をコンテナ化することで、マルチノードクラスタをローカルで簡単に立ち上げられるようにするツールです。要するにコンテナが動く環境ならどこでも使い捨ての Kuberentes クラスタを作成することができるわけで、発表中ではこの Kind を CircleCI 上で起動させて E2E テストを行う方法を解説しました。
形式手法による分散システムの検証
builderscon tokyo 2019 での発表です。
例えば決済処理がマイクロサービスに分割されている場合、複数のサービスに対して整合性を保ったままコマンドを発行するには工夫が必要です。この発表では一つの手法として TCC (Try-Confirm/Cancel) パターンを取り上げ、TLA+ を用いたモデリングと検査について解説しています。
余談ですが、この発表はタイムテーブル的に超人気セッションの裏番組になってしまい、集客が厳しかったです。こちらを聞いてくれた方の反応は割と好意的だったので、内容自体はよかったと信じたい。
TypeScript における型レベルバリデーション
We Are JavaScripters! @36th での発表です。
TypeScript は構造的部分型を持つため、一部の型引数を使用せず捨てる、いわゆる幽霊型を作成しようとしてもコンパイル時にチェックが効きません。そこで、区別したい型ごとに異なるフィールドを持たせた Branded Type を利用する方法を解説しています。
Kind で量産する使い捨て Kubernetes
CI/CD Test Night #5 での発表です。
CircleCI Community Meetup と同じく Kind を利用した E2E テストに関する発表ですが、今回はイベントの趣旨に合わせて「CI を Kubernetes で行う場合にどうやってクラスタを準備するか」という視点から解説しています。
従来、CI 用に Kubernetes クラスタが必要な場合、選択肢は「Pull Request ごとに Namespace を作成」もしくは「Pull Request ごとにマネージドクラスタを振り出し」のいずれかでしたが、Kind の登場により、簡単にクラスタを立ち上げて使い捨てることが可能になりました。
ライブで学ぶ The Elm Architecture
Meguro.es #23 での発表で、Meguro.es #21 の続編のような形になっています。
内容自体は前回と似ており、簡単なチャットアプリで The Elm Architecture の仕組みを説明しています。ただし今回は単に図解するだけでなく、ライブコーディングの要領でその場で一つづつ機能を追加していくことで、各動作がどのように実装されるのかについて順を追って解説しました。
GHCJS による Web フロントエンド開発
Haskell Day 2019 での発表です。
内容は Fun Fun Functional #1 での発表をよりリッチにしたものです。Firebase Realtime DB によるリアルタイムチャット機能に加えて Firebase Authentication を使用した Google ログインを提供し、会場にいた参加者にその場で書き込んでもらうデモを行いました。デモで使用したアプリケーションは以下に公開されています。
賢く「散らす」ための Topology Spread Constraints
Kubernetes Meetup Tokyo #25 での発表です。
この発表では、Kubernetes v1.16 でアルファ機能となった Topology Spread Constraints を取り上げました。複数の Node に Pod が分散している状況であっても、それらの Node が同じ Availability Zone やラックにホスティングされていた場合、障害により Pod が全滅する可能性があります。この問題を解決するため、Topology Spread では Node に Label を付与してグループ化し、そのグループ単位での Pod の分散方法を指定することができます。
CloudNative を学ぶにはまず KInd より始めよ
CloudNative Developer JP #13 での発表です。
ここまでにも何度か取り上げている Kind と、Topology Spread Constraints を組み合わせて発表しました。Topology Spread Constraints は実はかなりピーキーな機能で、設定を誤ると条件を満たす Node が見つからずに Pod が配置できない状態に陥ることがあります。ローカルに Kind で Kubernetes クラスタを作成した上でこの問題を実際に再現し、さらに修正するデモを行いました。
テスト駆動開発から証明駆動開発へ
July Tech Festa 2019 での発表です。
builderscon tokyo 2019 では TLA+ によるモデル検査を扱いましたが、こちらのテーマは定理証明です。
前半では builderscon と同様、通常のテストと分散システムとの相性の悪さについて述べ、分散システムに用いられるカオスエンジニアリングと対比する形で形式手法の考え方を導入します。また後半では、Curry-Howard 対応について触れたあと、Coq とそのフレームワークである Verdi を使用して分散システムを証明する仕組みを概説しています。
kube-batch による Gang Scheduling
Kubernetes Invitational Meetup Tokyo #4 での発表です。
複数の Pod が通信し合って実行を進めるような Job をデプロイする場合、一部の Pod だけが先に配置された状態で Node のリソースを使い切ってしまうと、後続の Pod が配置できずにデッドロックに陥ることがあります。これを防ぐため、特定のグループに属する Pod を一度に全て配置するか、あるいは全て Pending のまま留めるかという All of Nothing の配置戦略を Gand Scheduling あるいは CoScheduling と呼びます。
今回紹介した kube-batch は Gang Scheduling を実現する特殊スケジューラの一種です。Gang Scheduling 以外にも、複数のキューを定義してクラスタのリソースをキュー間で均等に配分するなどの機能が提供されています。
「詰める」と「散らす」の動力学
OpenShift.Run 2019 での発表です。
内容としては CloudNative Days Tokyo 2019 を元にした上で、いくつかの要素を追加して再構成しています。特に、CloudNative Days Tokyo 2019 時点では実装されていなかった Topology Spread Constraints への言及が追加されていますが、これは Pod の分散戦略を考える上で非常に重要な要素です。
2020 年の方針
さほど具体的になっているわけではありませんが、今後の展開についていくつか考えていることがあるので、振り返りのついでにここで表明しておきたいと思います。
カテゴリ間の連携
冒頭で述べた通り、現在のチェシャ猫の活動カテゴリは「Kubernetes を中心とした CloudNative 技術」「Haskell をはじめとする関数型プログラミング」「形式手法、特にモデル検査」の三つに分かれています。しかし残念なことに、現状それぞれのカテゴリでそれぞれ登壇するに留まっており、複数カテゴリを扱っていることがうまく活かせていません。
そこで 2020 年は、これらの知見をうまくつなぎ合わせることを目標にしたいと思います。三つのうち関数型プログラミングと形式手法は比較的近い分野ですが、これらと CloudNative を組み合わせようとする人はあまり見ないため、独自色が出せる部分なのではないかと睨んでいます。
より具体的には、「CloudNative + 形式手法」の組み合わせでもう少し面白いことができないかを検討中です。あるいはその過程で定理証明を採用することになれば、おそらくは Extraction の関係で実装には関数型プログラミング言語を使用することになるでしょう。いずれにせよ、複数カテゴリを横断したネタを作るのが目標です。
登壇以外の活動の充実
2019 年の活動は登壇に偏りすぎました。
今回並べた 19 件のスライドには、他に日本語情報が存在しないようなトピックも相当量含まれており、それなりに価値があるものだと自負しています。しかしブログのような散文と比較したとき、登壇スライドに載せられる(あるいは載せるべき)情報量はどうしても限られており、また検索性にも乏しいことから、インターネット上に蓄積される情報源としてはどうしても劣ります。
また、登壇だけにエフォートを割いていると、結局のところ「単に新しい情報を発掘してきて解説する人」になりがちで、自分自身、居心地の悪さを感じることが少なくありませんでした。少し前に Qiita で話題になった「Web エンジニア業界に感じた違和感」とも共通するものがあります。
結局のところ、いつも本質的な部分には踏み込まずに表面だけを撫でていて、マイナな技術のマイナさに便乗して素人相手に専門家を気取っているだけじゃないかという思いが常にある。
— チェシャ猫 (@y_taka_23) September 3, 2019
そこで 2020 年は、もう少し実務的な取り組みに力を入れたいと思います。より具体的には、kubernetes/kuberetens をはじめとする OSS へのソースコード貢献を継続的に行うのが目標です。また、登壇した際にはスライド公開に加えて、扱った要素技術について、ある程度踏み込んだ解説を参照可能な形でブログに記録しておきたいところです。
海外カンファレンスでの登壇
読んで字の如く、一度はやってみたい海外登壇です。まったくノープランですが、とりあえず出せそうなカンファレンスを見つけるところから始めたいと思います。
まとめ
本記事では、2019 年に行った計 19 回の外部発表について、スライド公開までで終わっていてブログ化されていなかったものも含め、簡単な解説を付けて一覧にしました。
さらに 2020 年の活動方針として「CloudNative と形式手法の統合を狙うこと」「登壇以外の活動にも力を入れること」「海外カンファレンスで登壇すること」の三つを設定しました。
ここで設定した 2020 年の目標が果たして達成されるのか、判明するのはまた 1 年先ですが、それはまた別の話。
OpenShift.run 2019 で Kubernetes のスケジューリングについて話してきました
先日行われた OpenShift コミュニティのイベント OpenShift.run 2019 にて、Kubernetes Scheduler とその関連ツールについて講演してきました。公募 CFP 枠です。
OpenShift のイベントでありながら、OpenShift についてはまったく触れずひたすら Kubernetes の内部実装を解説する異色の登壇でした。実際、40 分枠の講演の中で(RedHat 社以外も含め)ベンダニュートラルな立場で登壇したのは自分だけだったようです。これは私見ですが、逆に言えばそういう内容でも CFP 採択されているというのは、運営側も「単なるマーケティングイベントにしない」というスタンスなのかなと思います。
なお今回の発表は、CloudNative Days Tokyo 2019 での講演が元になっています。こちらについては参考文献や当日出た質問など補足情報を含めて以下の記事で扱っているので、今回のスライドと一緒に読むとより理解が深まるはずです。
CloudNative Days Tokyo 2019 からのアップデート
見比べていただければわかる通り、今回のスライドは図解などかなりの部分を前回から引き続き使用していますが、各ツール・機能を紹介する順番など全体の構成がやや異なります。これはプレゼンのテーマ性をより強く押し出し、Scheduler の仕組みを学ぶ上での動機を強調するためです。
また、CloudNative Days Tokyo 2019 は 7 月の開催だったため、それから 五ヶ月の間に Kubernetes 自体にもいくつか進展が見られます。
キーワード「詰める」と「散らす」
前回の発表ではモチベーションの部分を特に述べることなくいきなりスケジューリングの話に入りました。これに対して今回は、タイトルにもある通りサーバ上にコンテナを「詰める」と「散らす」という二つのキーワードを設定しています。その上で、両者のバランスを考える上で「戦略」が必要であり、戦略のためには「仕組みへの理解」が必須なのだ、という導入です。
これはある意味では OpenShift の考え方、すなわち Kubernetes とそれにまつわる Image 管理などのエコシステムをラップする考え方、とはやや方向性が異なるものです。冒頭で自分だけ非ベンダ所属だという件を書きましたが、こちらの点でも異色な印象を与えたかもしれません。
今回のプレゼン自体の戦略を別にしても、「仕組みの理解」は自分自身が技術と向き合う際に重視している観点でもあります。「なんか知らんがよしなに動く」という表面的な事象に対して、「実は裏側には色々な仕組みがあり、それらは知るに値するのだ」というチェシャ猫の哲学を感じ取っていただけたなら幸いです。
Pod の Topology Spread Constraints
完全な新規要素として、Kubernetes v1.16 でアルファ機能として導入された Topology Spread Constraints について追加しました。
Topology Spread は、ユーザ側で Node に Label を付与することで故障ドメインを表現し、Pod の配置の際に故障ドメインをまたいだ分散を考慮することができる機能です。Kubernetes Meetup Tokyo 第 25 回でも登壇したので合わせてご参照ください。
今回は OpenShift のイベントでオンプレ運用勢が多いだろうという予測のもと、発表の際には口頭でラック障害についてちょっと触れたりもしています。
Scheduling Framework
Scheduling Framework は、Kubernetes 本体の実装の中でスケジューリングアルゴリズムの一部を interface として定義することで、レイテンシを維持したまま拡張性を提供するためのプロジェクトです。前回の発表のときは大した内容がなかったのでカットしましたが、時間経過によって重要性が増してきたと思われるので、今回はほんの 1 ページですが触れることにしました。
特に Kubernetes v1.17 では、既存の kube-scheduler の実装を Scheduling Framework のプラグインとして移植する試みが進められています。CHANGELOG では [migration phase 1]と呼ばれている項目です。
- Scheduling Framework(未実装部分を含む全体のデザイン)
- Kuberentes v1.17 CHANGELOG
- 猫でもわかる Scheduling Framework(情報がちょっと古い)
まとめ
今回は OpenShift.Run 2019 でプロポーザルが採択され、Kubernetes のスケジューリングについて、CloudNative Day Tokyo 2019 の講演を再構成する形でお話ししました。「スライド使い回しじゃん」という懸念もちょっと頭をよぎったのですが、前回とは参加者のクラスタが異なることもあり、Twitter で観測した限りでは会場の反応は概ね好評だったようです。
ところで、今回紹介した Scheduling Framework には Wait および Permit という「合図が来るまで配置を保留」という機能がありますね? 一方で、数日前に別のイベントで「Pod の配置を保留するために kube-batch が開発されている」という説明をしています。それぞれについては語るべきポイントがあるのですが、それはまた別の話。